At VMware we’re working on technology to support Spatial Computing in the enterprise. If you’re not familiar with Spatial Computing, please check out my blog here. Spatial Computing is the convergence of emerging technologies such as Augmented Reality (AR), Virtual Reality (VR), computer vision, depth sensing and more.
In this blog I’m going to cover our experiences around building immersive training scenarios for mobile or standalone virtual reality headsets. Specifically, I’m going to dive into using a scene simplification technology by Google called Seurat. Unfortunately, Seurat is not officially supported by Google, but it is an open source project that can be used and updated by anyone. The first part of this blog will introduce immersive training and scene simplification. The second part of this blog is a technical how-to on Google Seurat.

Image credits: Google/ILMxLAB – Google Seurat has been used to deliver film quality environments on mobile VR devices.
My role, as Director of AR/VR at VMware, is to lead our product strategy around spatial computing with a focus on research and development of these technologies. In the build-up to VMworld 2019 we wanted to put together a few demos to showcase what our team had been working on (Project VXR). Given the short timelines, it was all hands to the pump and with a (short!) background in software engineering I was happy to get hands-on and contribute. It’s not often I get to stretch my technical legs, so this was certainly a fun and challenging project for me.
Immersive Training is the top use case for Virtual Reality in the enterprise
Immersive training is one of the top use cases for virtual reality in the enterprise. The ability to train people in a safe, risk free, low cost virtual environment and the ability to simulate and record different scenarios is game changing. Studies show that training in VR is more effective for physical/complex tasks and procedures than traditional training methods.
In order to build immersive training scenarios, you need realistic environments and objects so that the user has an effective learning experience. When I say realistic, I mean that the environment represents the one a user will be operating in in real life. This doesn’t mean photo-realistic rendering, but that the building, room and objects they interact with have the correct scale, shape, key features and details. In order to achieve this in VR, you need access to 3D models that represent your environment.
Virtual Reality has certain challenges when using existing CAD data for immersive training
Fortunately, most enterprises will have access to the Computer Aided Design (CAD) data and models for their existing buildings and products they are assembling or maintaining – or access to those product models via suppliers. Other objects that they may need to simulate will often be available on the various 3D model marketplaces online. For example, one of our demos involves the assembly of a rocket engine and the model was readily available online in a format we could use.
Unfortunately, the reality is that CAD models often can’t be used in Virtual Reality without some form of simplification, decimation or a process known as baking. The reason for this is that VR (and AR) requires consistently high display frame rates to maintain a comfortable and effective experience. In order to deliver the required frame rates, there’s a target for the number of draw calls and polygons displayed per frame on current GPUs. On mobile/standalone VR headsets the number of polygons is targeted to around 100,000 per frame. On PC based VR headsets, the target is often somewhere between 500,000 to 1,000,000 per frame.
CAD models usually have millions of polygons and therefore might not be suitable in their current form for VR. Our rocket engine model with over 8,000,000 polygons and its associated rocket factory CAD model could not be used in VR without a reduction in the number of polygons.
Scene Simplification can deliver high fidelity experiences for certain training use cases
In this blog series I’m going to focus on how you can use existing CAD building models or high poly scenes with millions of polys in VR using a scene simplification technology from Google, called Seurat. Scene simplification aims at reducing the number of polygons and draw calls for the scene in order to provide a high-fidelity experience. Scene simplification relies on the fact that in VR it’s likely that the user will be doing most of their activities within a set boundary. This means that the user will probably stay within a small area (anywhere from 1 to 5m²) when being active in VR. By limiting the movement of the user to a set “head box” we can create a 3D model of what the user would see from within that head box, without needing every polygon.
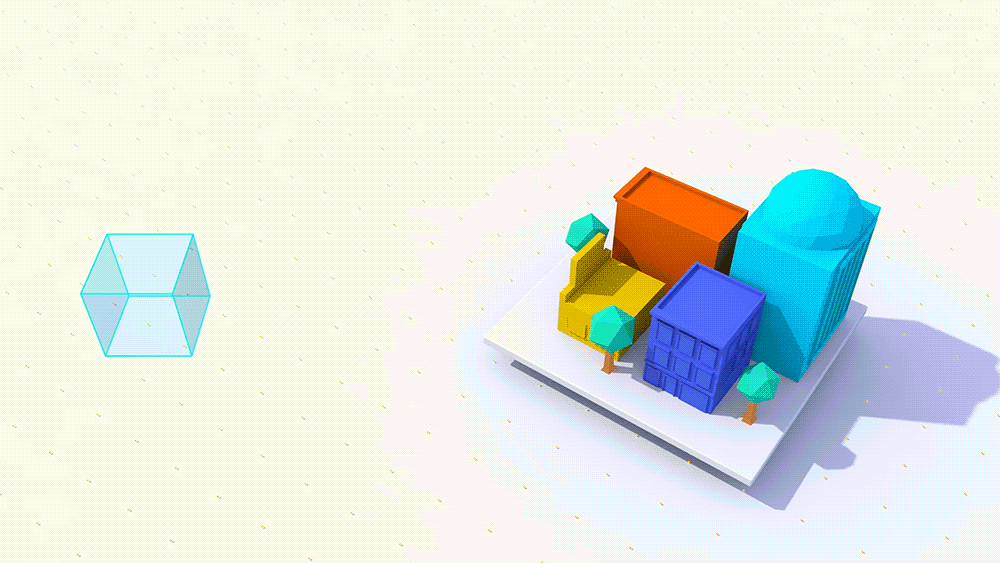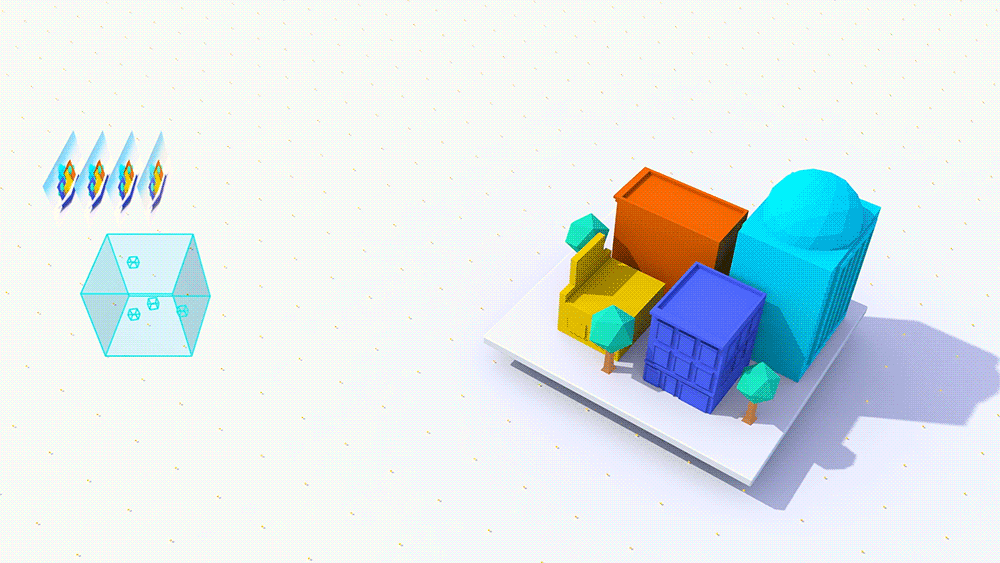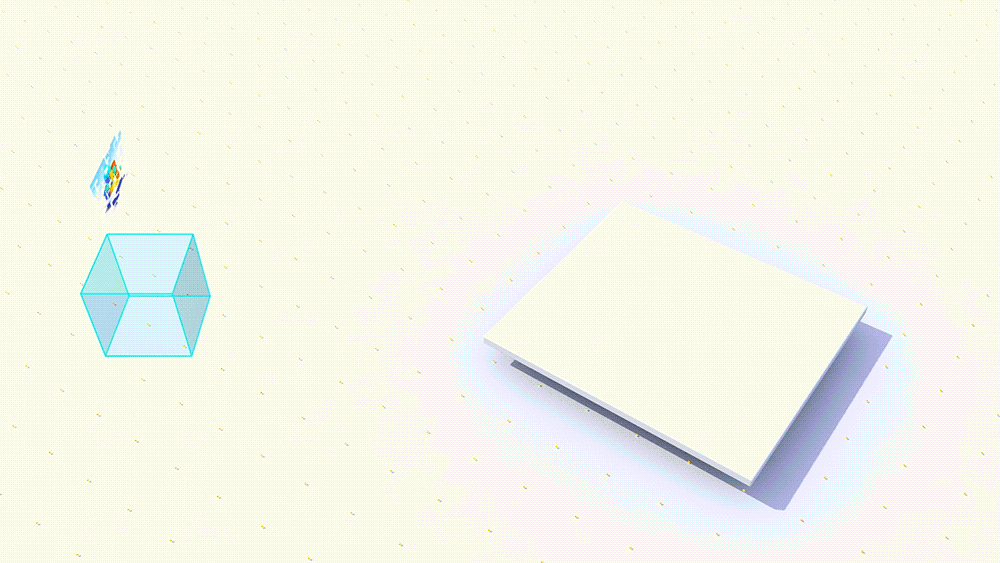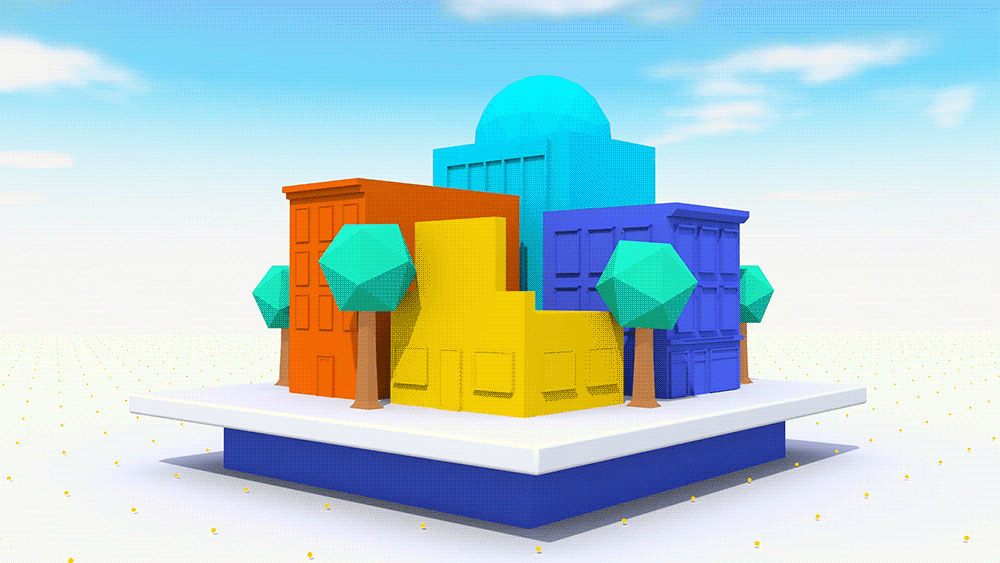 Image credit: Google – Example of how Google Seurat works to simplify a scene
Image credit: Google – Example of how Google Seurat works to simplify a scene
Of course, if your training requires a user to move about an environment more than a few meters, scene simplification may not be the ideal solution. There are alternatives to scene simplification such as object decimation, where complex objects have the number of polygons reduced through an iterative process that reduces detail on the model. Object decimation is out of scope for this blog as is high poly baking.
In my example I’m using environments with 50,000,000+ polygons and using Google Seurat to reduce that count to less than 100,000 polygons, with little in the way of reduced fidelity. Google Seurat allows us to bring immersive environments into mobile VR experiences.
Quelle:
Immersive Training Environments for Virtual Reality using Google Seurat – Part 1

