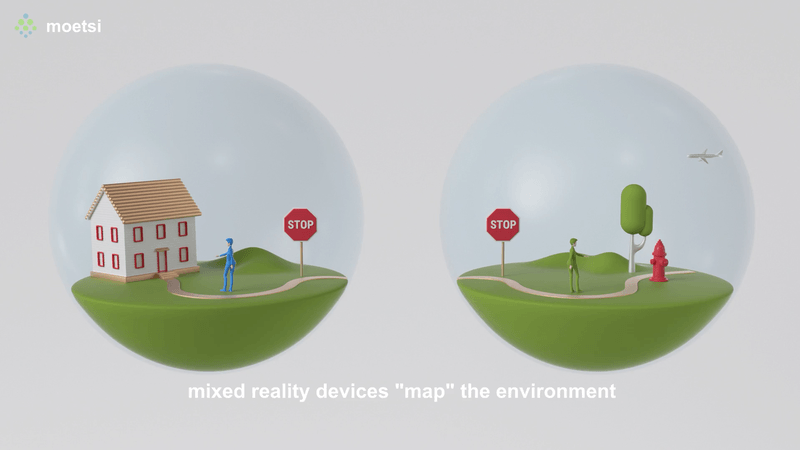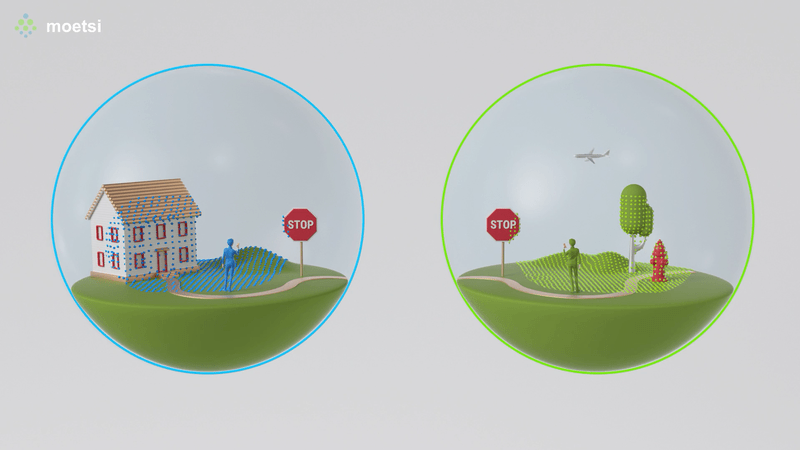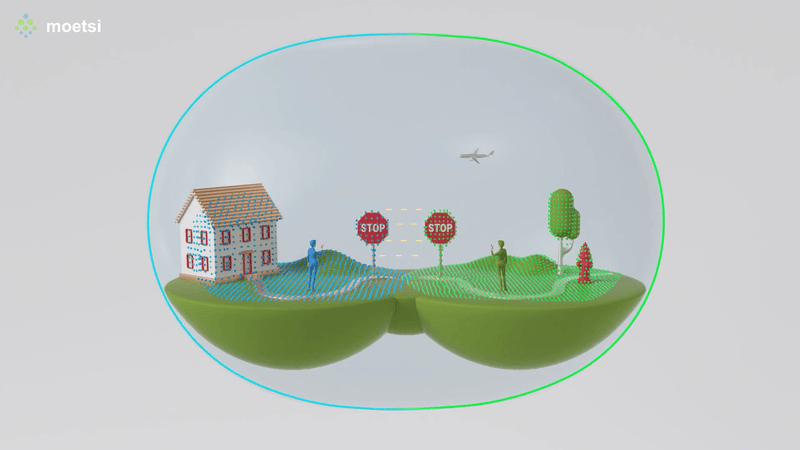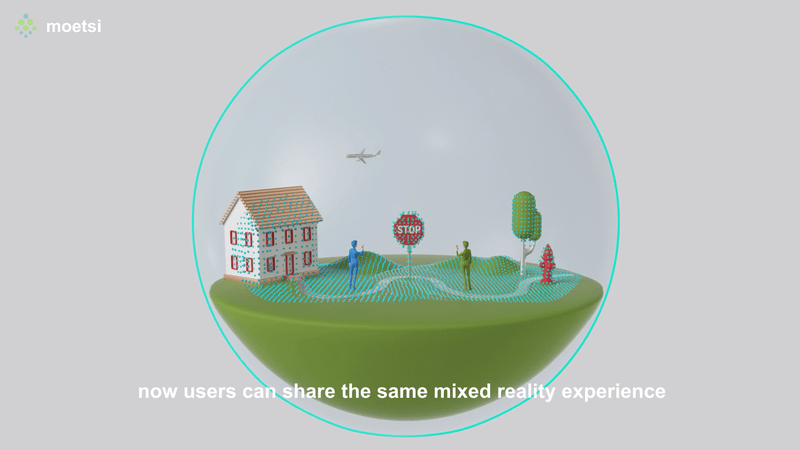
I’m standing over a table, looking at a 3D architectural model of a room. Then I hit a button, and suddenly I’m inside the model itself. I can walk around, get a feel for the space, see how the plumbing and lighting systems intersect, and flag any potential problems for the room’s designers to tweak.
Of course, I haven’t actually shrunk into the table: I’m wearing a headset in an architectural virtual reality app. Over the past few years, more and more architects have started to incorporate immersive VR tools in the process of designing buildings. VR, they say, helps them understand spaces better, facilitate better collaboration, and catch errors they might not have otherwise. These architects hope that as VR technology improves and becomes more commonplace, it could fundamentally transform the way that they approach their jobs, and lead to more efficient and effective design.
But there are also architects who feel that the current spate of VR products does not yet live up to the hype put forth by technologists. “We have questions we can already very effectively answer in 2D on a screen,” says Jacob Morse, the managing director at the architecture and design firm Geniant. “Putting it in goggles is just a gimmick.”

Building from scratch with the headset on
For decades, architects have designed buildings starting with 2D blueprints, which require technical knowledge to fully comprehend. When it comes to design, working in two dimensions is “not a natural experience,” says Jon Matalucci, a virtual design and construction manager at Stantec, a global design and engineering firm. “We experience things in 3D, and there’s a loss in translation.”
Prior to a few years ago, using VR was prohibitively expensive for many architects, and it took far too long for design programs to render 3D spaces. But upgrades in both hardware and software mean that many architecture firms now own VR headsets, whether it be the Meta Quest or the Google Cardboard. Design tools like Revit and Rhino turn blueprints into 3D digital models. And in programs like Enscape and Twinmotion, architects can walk into spaces they’ve designed within minutes of creating them.
The architect Danish Kurani, who runs his own design studio, has been using VR tools for seven years. Early on in the process of designing a room or building, Kurani puts on a headset to view proposals created by architects on his team and talk through different options. When they’ve finished their preliminary designs, he then gives his clients guided tours to get them excited and to solicit feedback. During our interview over Google Meets, Kurani takes me through a virtual rendering of a nonprofit entrepreneurship center for kids that he designed in Baltimore, its rustic brick walls lined with 3D printers and other tools.

“As we walk around, I’ll ask them questions like, ‘Is this enough space in front of the laser cutter?’” Kurani says. “They’re really appreciative of being able to see it this way as opposed to looking at abstract black and white lines on a floor plan. They’re really able to immerse themselves.”
Kurani says that VR allows him to detect subtle design problems that he might not have noticed on a screen. Walking around a classroom in VR with an audiovisual engineer, for example, lets them figure out the best placements for cameras so that remote teachers can clearly see their students and vice versa. Being in VR also allows Kurani to see if an exit sign might block the view of a student sitting in a back row who is trying to see a presentation on a high projector screen.
Matalucci, at Stantec, says that his company now has the ability to “put a headset on every desk.” The company is a customer of the design software powerhouse Autodesk, and its employees were among the first users of Autodesk’s Workshop XR, a 3D design review software which was announced in November and is available in beta. The software allows architects to virtually step into their creations at a 1:1 scale. One of the projects that Stantec recently used Workshop XR for was a hospital in rural New Mexico. Matalucci says that VR is especially useful in designing healthcare buildings because of all of the overlapping systems required in them, from process piping to oxygen to electrical.
VR helped Stantec’s designers receive feedback from clients and make tweaks in real time, Matalucci says. They even sent VR demos to night-shift nurses to see how they felt moving around the virtual hospital’s halls. “We were populating the facility with features based on their requests. At any moment when they wanted to see where we were in the process, they were able to put on their headset and go to remote rural New Mexico, giving them visibility into a very complex process,” he says. “As a result, we were getting answers to questions that we didn’t even think to ask.”
Experiencing Workshop XR myself, via a Meta Quest 3 headset,is a surreal experience. With the help of Autodesk XR product marketing manager Austin Baker, I teleport in and out of architectural models and fly around a Boston municipal building, seeing how its grand staircase unfolds into a large atrium. I can trace how sunlight and shadows move across the floor. Theoretically, dozens of different people working on various aspects of the project could convene here, hashing out decisions in real time before a single brick is laid.
“What would have been dozens of back and forth emails, Zoom calls, and trying to share renderings of our 2D data is now a 15-minute intuitive walkthrough, where we have all the data at our fingertips,” Baker tells me, his avatar floating next to mine. “We’re able to spot issues that could cost millions of dollars downstream.”
Steffen Riegas, a partner and lead of digital practice at the Basel-based firm Herzog & de Meuron, says that VR has been especially useful in designing and reviewing complex interior situations like staircases. “It’s really hard to communicate those narrow vertical spaces and depth in two dimensions; it’s almost impossible,” he says. “VR solves that.”
Herzog & de Meuron has incorporated VR and XR (extended reality) tools into many parts of its practice. The firm’s partners and project teams sometimes don headsets to make design decisions. And the company’s architects even took Microsoft’s HoloLens—a mixed reality headset that allows users to project virtual objects onto the real world—onto an actual project site in Basel, to see how their new building designs might look next to the physical ones already there. “If you want to get an impression of what a site will feel like, it’s difficult to experience or illustrate that with drawings,” Riegas says. “But with XR, you can walk to the other side of the block and see how a new building will look from different perspectives.“
 Stantec architects discuss a design project inside the virtual workspace Workshop XR. Stantec
Stantec architects discuss a design project inside the virtual workspace Workshop XR. Stantec
The limitations of current VR tools
But the current VR tools are not universally hailed by architects or other professionals in the design space. Kurani says that he’s encountered general contractors and subcontractors who are resistant to using these new tools due to the learning curve, which makes integrating them into processes less worthwhile. “If subcontractors can’t use the technology, then you’re wasting time and energy,” he says.
Jacob Morse, at Geniant, says that from what he’s seen, many architects use VR goggles only as a marketing tool, as opposed to integrating it into their design processes. “I’ve yet to see the compelling use cases, apart from selling and presenting, that really push the field of architecture forward,” he says. “At large, it hasn’t unlocked completely new insights and new solutions that we can’t accomplish in desktop computer programs.”
However, Morse does hold out hope that as headsets and software and software improve, VR could allow him and other architects to approach design as a more iterative process, using it to research, prototype, and test how people respond to slight tweaks in their virtual environments. David Dewane, the chief experience officer of physical space at Geniant, hopes that VR could also be used in education: to allow students to virtually accompany an elite design team from conception to construction, or to study the most famous buildings in the world up close.
Quelle:
Foto: Photo illustration by TIME; Getty Images
https://time.com/6964951/vr-virtual-reality-architecture-meta-quest/