TL:DR; We think there are 4 core problems in mixed reality: tracking, relative position, environment digitization, and object digitization. We define these problems and the benefits of solving them with an edge processing architecture.
In our first post we announced the Sensor Stream Pipe (SSP), a tool with the goal of eventually powering future mixed reality experiences with live data from multiple sensors and edge hardware.
In this post we explain how using SSP with edge hardware can improve current mixed reality experiences.
4 problems to be solved in mixed reality experiences:
- Tracking (how a device is moving)
- Relative Position (where a device is relative to something else)
- Environment Digitization (the environment a device sees)
- Object Digitization (the objects a device sees)
People that work on solving spatial computing problems might find this a funny break down because tracking (#1), relative position (#2), and environment digitization (#3) are often all results of a single problem network. We do not define each problem by a unique set of mathematical techniques, but by the unique benefit a solution provides mixed reality experiences. Solving #1 provides the ability for virtual objects to stay in place in the physical world, solving #2 allows for multi-user experiences, solving #3 allows for virtual objects to better interact with the physical world and allows for in-depth analysis of a physical area, and #4 allows for virtual objects to interact with real dynamic objects.
We dig into what these problems mean to us and how our edge processing architecture powered by SSP can provide benefits to mixed reality developers. If you are interested in helping out or would like us to help you out, feel free to reach out.
Tracking
Tracking device location is key to mixed reality experiences. By knowing where a device is, an application can render virtual objects that appear to exist in the real physical world. If the application knows that the device has moved a little to the left, it can render an image of a virtual object as if it had moved a little to the right, thus creating the illusion of permanence in the physical world.
There are a lot of really good in-depth explanations on how tracking in AR works (here, and here). An overly-simplified explanation is that the device takes in visual information (what it sees) and intertial information (how it feels) and tracks the phone’s position in 6 degrees of freedom (where you are in 3D space) in real-time (~30 updates a second).
However, there are problems associated with processing sensor data locally on the device. If sensor data is locally processed, it accumulates “Tracking Drift”: the delta between where a device thinks it is and where it actually is. The more sensor data is collected, the more Tracking Drift increases and compounds (drifting from its true location)¹. This drastically diminishes the quality of mixed reality experiences.

Tracking Drift causes the rendering of virtual objects to drift in the physical world. The accumulated tracking drift means the application thinks the device is somewhere it is not. This results in projecting virtual objects incorrectly.
Edge processing can use powerful hardware to do more accurate global tracking optimizations. Stanford’s BundleFusion is a great demonstration of how fast & accurate tracking can be when utilizing a workstation for processing.
This does not mean that edge processing can completely replace local on-device tracking (meaning, the tracking math that processes on the actual mixed reality device, like a Hololens). For tracking results in the sub-second scale (how the device moved in the last second), local devices will likely always be superior because of the low-latency of results. But, using local on-device tracking in addition to edge optimizations can provide a better mixed reality experience.
Processing Flow
- Device streams sensor data to edge hardware
- Edge hardware computes an optimized tracking position
- Edge hardware sends the updated tracking position back to the device
- Mixed reality application updates the device’s location

Local tracking can be supplemented with optimized tracking updates from the edge hardware to provide a better Mixed Reality experience.
Relative Position
Understanding a device’s relative position to another device is how multiple users can share the same experience. When users know their relative position to each other, they see the virtual object in the same location. Shared mixed reality experiences are hard (6d.ai wrote a great in-depth explanation on this topic) but we think getting shared mixed reality experiences right is worth the trouble.
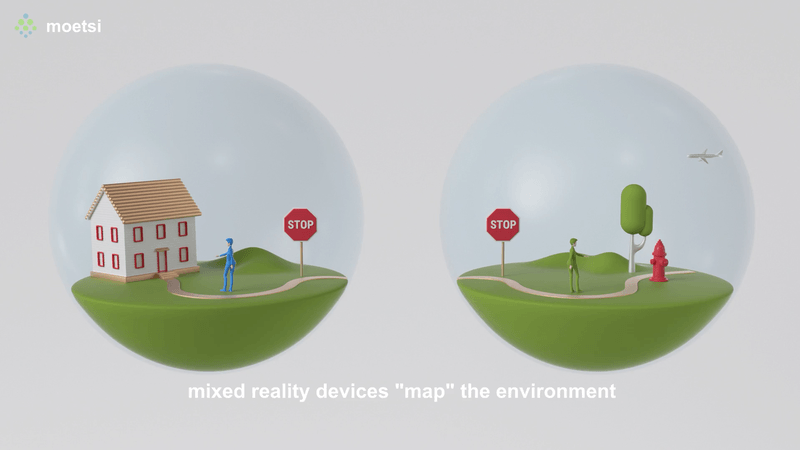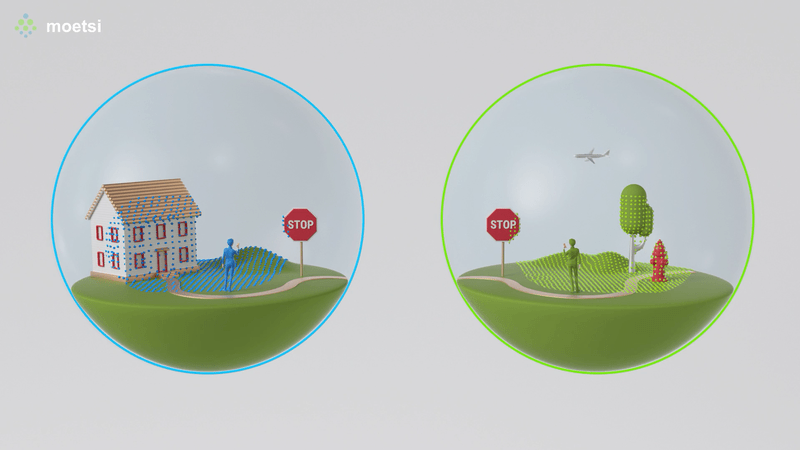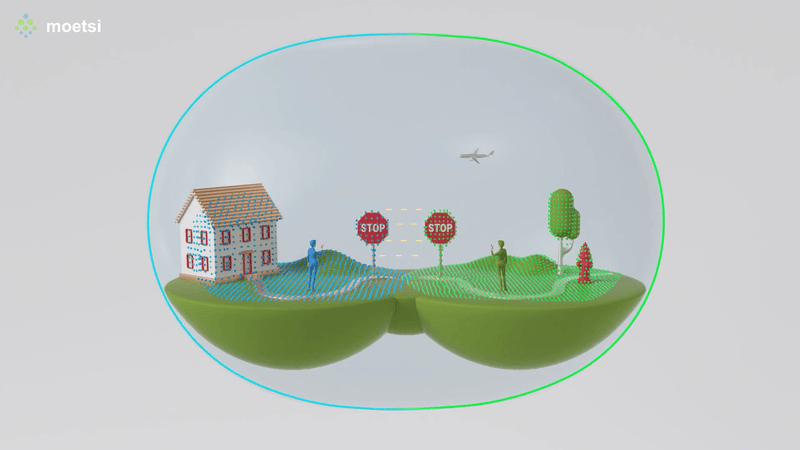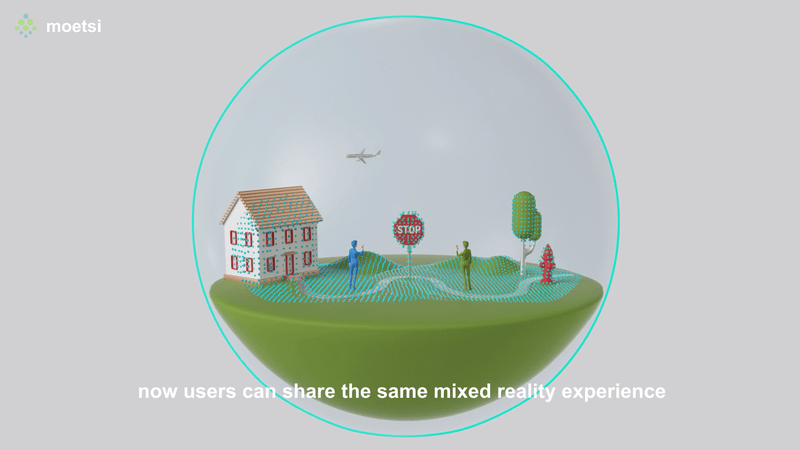
The process of finding your position relative to a known area is also known as “relocalization.” If someone told you that they were in the middle of your kitchen facing the sink, you would know where they were because you know the spatial layout of your kitchen. That’s basically how finding Relative Position works — devices map their immediate physical surroundings, other devices can find their position relative to those mapped areas, therefore by the transitive property, devices find their relative position to other devices.
Here’s the current relocalization flow without edge hardware:
- An initial device scans a small area collecting raw sensor data
- The device processes the sensor data to create a small “map”
- The map is uploaded to either the cloud or another device
- A second device downloads the “map”
- The second device scans the same area as the “map”
- The second device processes its sensor data and compares it to the “map” to find its relative position

This is the approach used by Apple’s ARWorldMap, Microsoft’s Spatial Anchors, Google’s Cloud Anchors, and 6d.ai, and it works without needing high network connectivity.
However, solving this problem with edge hardware opens up the option to keep track of all scanned areas from all-time and quickly matching incoming sensor data with anything previously covered. This approach requires high networking capability, but it has the benefit of a constantly increasing and adding to all-time covered area.
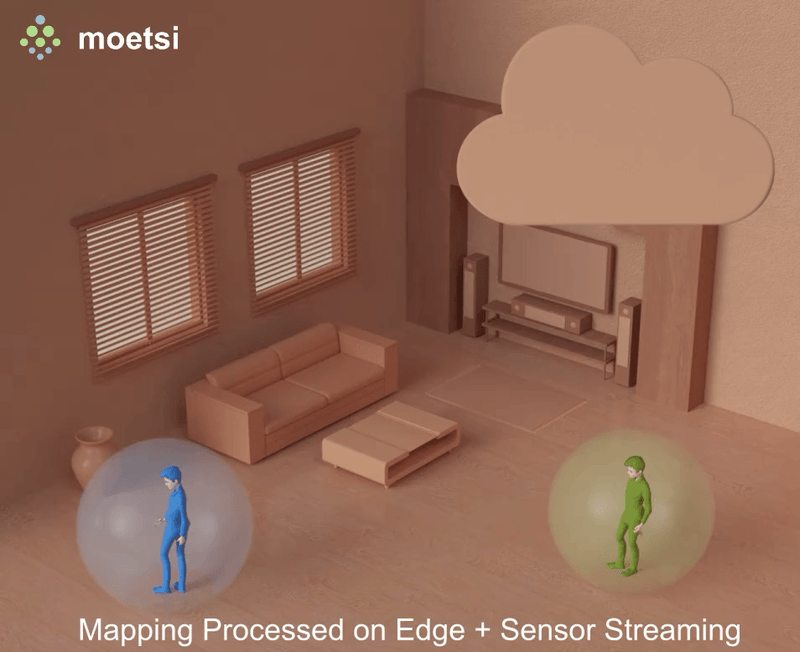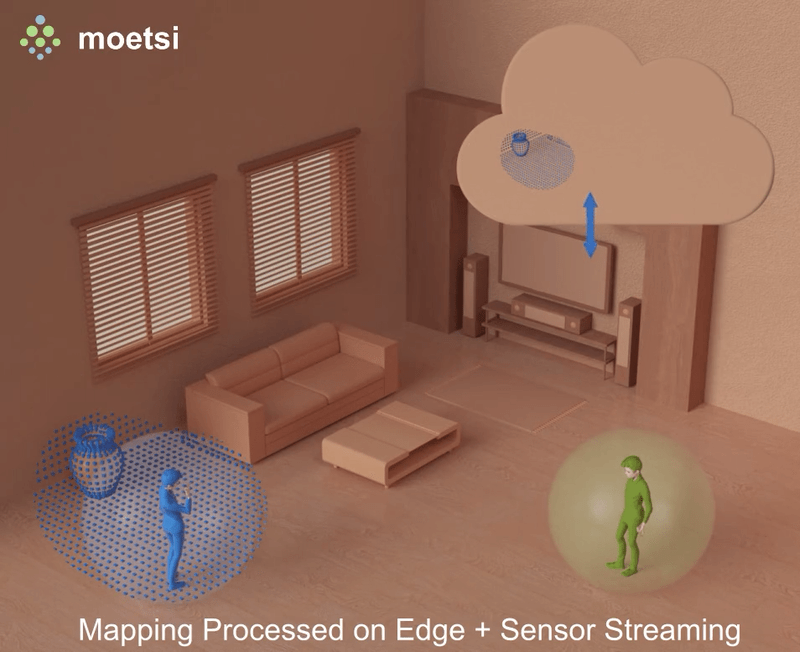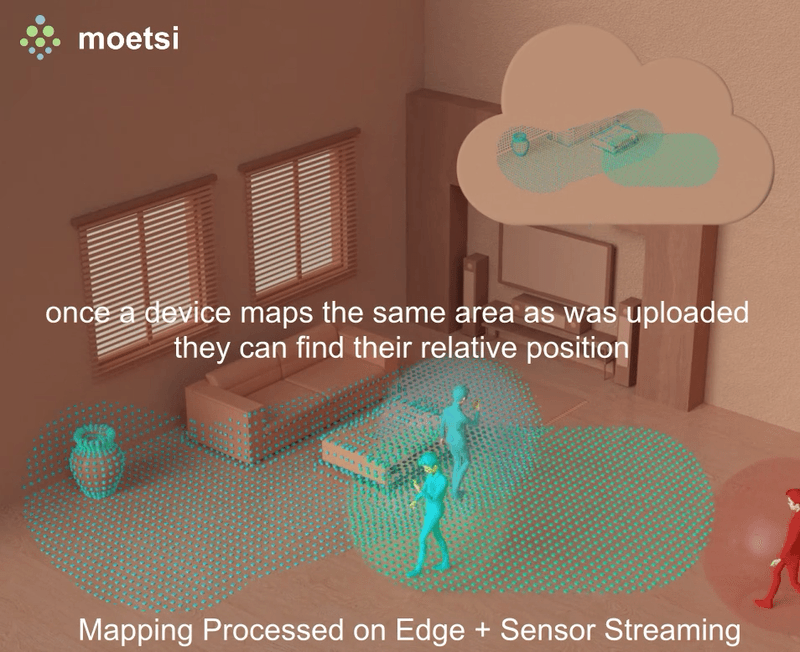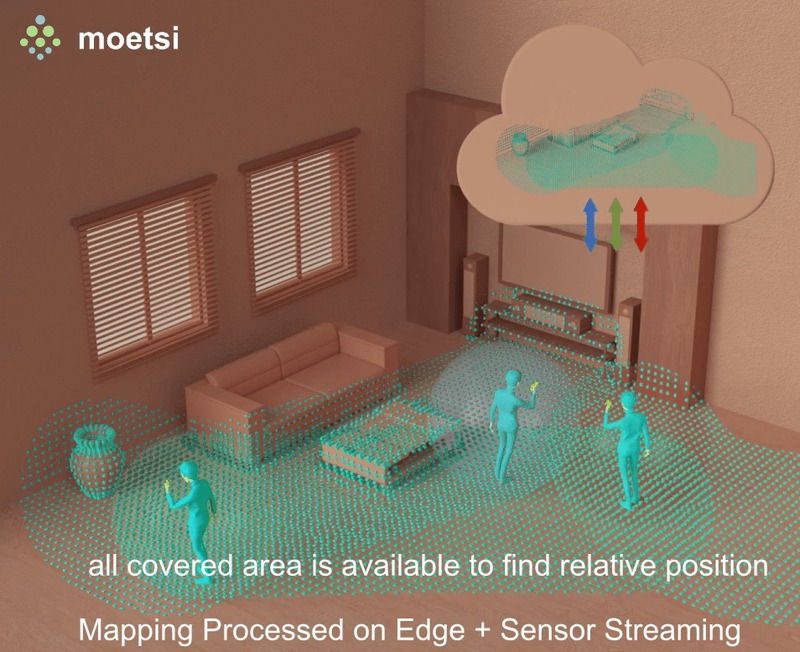
This approach allows for much faster re-localization and an ever-increasing “map.” As soon as 2 sensor streams see even a tiny bit of the same area, they instantly have access to each other’s complete, dynamic, always-expanding maps. This could be great for mixed reality experiences where 2 users are in a new location and need to interact with each other near-immediately.
Additionally, this approach can be used for output-only device like the Azure Kinect or “dumb” cameras that can only output data and do not perform any processing themselves. These devices cannot “receive” an environment fingerprint to relocalize to, because they do not have processing hardware (as opposed to an iPhone or HoloLens). The edge server can do the processing of relocalization and provide the devices’ relative position to whoever needs it.
Environment Digitization
Environment digitization is a similar problem to relative position, both problems require mapping a static area, but environment digitization needs to go further and accurately reconstruct an environment, not just “fingerprint” it. When sensors map an area they compute “feature points” — interesting and identifiable traits (the opposite of a blank white wall). These feature points act as a fingerprint of an area which is enough to recognize the area and compute relative position, but not enough to get a good idea of what the environment looks like with any fidelity.
Environment digitization, or “environment/3D reconstruction” is a hard problem to solve. It requires connecting different points in 3D space with the correct surface topology. Digital sensors collect data as discrete points in space (like pixels in an image), so if a sensor is scanning a surface and if a small area does not have data, is that a bad reading or does that surface have a hole in it? If using a point cloud, what points do you show to best represent the environment? If constructing surfaces, do you use a TSDF and marching cubes on the entire dataset, or do you follow a more semantic understanding pipeline?
Two current benefits of environment digitization are:
- helping virtual objects behave correctly, and,
- producing a “digital twin” for creating a 3D model.
Mixed reality applications need to have an understanding of the surrounding area to be able to make virtual objects behave correctly. “Plane detection” is a key abstraction for most mixed reality SDK’s (ARCore, ARKit, and MRTK all have their own solutions). A virtual ball “bouncing” 6 inches through the floor doesn’t create the illusion of it existing in reality. “Occlusion”, or hiding virtual objects behind real things, requires understanding the environment as well. You wouldn’t expect your virtual pet to still be visible as it turns a corner into another room.
Being able to get a high-quality understanding of an environment also has applications outside of mixed reality experiences that are usually top-of-mind. Scaled Robotics is “digitizing construction”. Their mapping device travels a construction area and produces a digital copy of current progress. This is then used to find any discrepancies between what has been constructed, and what should have been constructed, saving everyone a lot of time and money. This is a “digital twin” use case that doesn’t need real-time environment digitization, offline processing works fine.
Of the 4 problems in digitizing reality, environment digitization probably is the least helped by edge processing. In unexplored spaces, on-device environment digitization for mixed reality applications is already capable. 6d.ai is able to do unbelievably fast and accurate digitization using only the RGB sensor on mobile phones (check it out, it’s pretty outrageous). Environment digitization for non-mixed reality applications (like Scaled Robotics) usually don’t need to immediate understanding from sensor data, and offline processing works just fine.

An edge processing approach to environment digitization may be helpful for response teams in disaster areas to communicate with remote teams, but the same utility could probably be provided by batch processing collected data (an approach like COLMAP or Microsoft’s Building Rome in a Day).
Using edge processing for environment digitization increases the speed of reconstruction both because of real-time processing and also because of real-time feedback on what areas have been covered (so less rework). It is also an architecture where engineers only have to implement their pipeline once, on a single computing platform (edge hardware), instead of reimplementing for each device platform (like 6d.ai had to for Android and iPhones). Additionally, off-device processing is the only way that sensor-only devices with no processing power can provide benefit.
Object Digitization
We define “objects” as tangible, dynamic entities in the real world, which a device cannot scan to find its Relative Position. Objects are different from “environments,” but this definition gets tricky because the distinction between objects and the environment isn’t always simple. Trees seem like they should be considered as “environment” (they don’t walk around) but they also grow and change leaves. Cars are usually objects, but a car that hasn’t moved out of a driveway in 25 years could provide Relative Position. In general, if a physical entity doesn’t move or change a lot, we consider it as “environment.” If it does, we consider it an “object.”
Here are two sub-problems that need to be solved for in Object Digitization:
1) what is an object and
2) where is the object in 3D space.
For computer vision software to know what an object is, it must know the type of object (hot dog or not a hot dog) it is, and also the boundaries of the object pixels (semantic understanding) in the frame. While it is possible to create a digital representation of an object without knowing this information (@MrCatid was able to stream his dog in 3D with volumetric streaming just fine), we think the practice of defining objects can open up new opportunities like object behavior prediction and is worth the effort (even if it is so hard that a new object dataset recently stumped all current computer vision models).
Understanding where an object is requires tracking it (is it the same object between video frames?) and knowing its pose (where is the object’s center origin (0,0,0) and where is it facing?). Currently, we think that Pose Estimation (understanding where the center origin of an object is) will be more important than high fidelity reconstructions of the object. As such, Pose Estimation is where we at Moetsi are focusing our efforts.
Microsoft Research has done incredible work with real-time high-fidelity object digitization. The renderings are so unbelievably hi-fi that you can see the wrinkles in someone’s shirt. Very cool, but there haven’t been many compelling use cases of such technology other than the promise of 3D video-conferencing.
Instead, digitizing key-points of objects seem to have made more of an impact. Leap Motion is a company that focused solely on hand-digitization because of its applications in interacting with virtual and augmented reality headsets. Microsoft and Apple have released body digitization solutions that provide key points rather than high fidelity reconstructions and also have had interesting use cases.
Detection + Tracking + Pose = Digitization
Object Digitization algorithms can run locally on devices without much issue. The hardware requirements to run a machine learning model are a lot less demanding than those required to train a machine learning model. Running these models locally (as opposed to remote processing) is also important for mixed reality applications with virtual objects to ensure a perfectly seamless experience. The same problem of occlusion discussed in Environment Digitization also applies to Object Digitization– a virtual object should not be visible if a real person (in the real world) steps in front of it.
However, there are benefits of streaming sensor data for edge object digitization versus local processing. Running object digitization algorithms on edge hardware means you only need to deploy pipelines on a single platform and it allows devices without dedicated processing hardware to also provide value.

In contrast to environment digitization which usually has a general pipeline (pipeline ingests all data and reconstructs a “ surface” rather than discrete items), object digitization might need to have a specialized pipeline for every single object type (just like Hand and Body Object Digitization). This might mean that each type of important object will need its own pipeline: a car pipeline, a dog pipeline, a bike pipeline, etc, which might be more than a mobile device’s local processing can handle.
More likely, object digitization will be a collaboration between local processing and edge processing, like tracking, where processing is both done locally and on the edge. An inspiring possibility resulting from digitized objects available on the edge is that mixed reality users could then have awareness of things they can’t even see.
Putting it Together
We think that solving these four problems with an architecture that can scale with increasing sensor data will create a base infrastructure for mixed reality applications.
Remote observers can have a real-time “sims view” of an area:

And users within the area will have situational awareness and understanding powered by all sensors in the system:

With additional layers of understanding like prediction and labeling we will be headed towards local area omniscience.
Our Roadmap
1. (2019) Sensor Stream Pipe (SSP) ✅
We have released the Sensor Stream Pipe. It has interfaces for Azure Kinect as well as interfaces for seminal spatial computing datasets (more interfaces coming).
Hopefully our explanation above of how we see things gave enough explanation of its purpose and what it does, but if not the README is pretty solid.
2. (2019) SSP Microsoft Body Tracking SDK interface ✅
B-b-b-b-b-bonus release. We have created a Sensor Stream Client interface that works with algorithms for the Azure Kinect. This way when you stream your Azure Kinect data using Sensor Stream Pipe to hardware for further processing you can actually use the Microsoft Body Tracking SDK.
Not really interesting to stream data if you can’t do anything with it which brings us to…
3. (2020) Multiplayer Mixed Reality Unity DOTS Tutorial / Sample Project ✅
The Unity Sample project will be a multiplayer game where users will be able to join and navigate similar to a game like Minecraft.
Will utilize Unity DOTS (Unity’s ECS), Netcode and ARFoundation. Non-AR players and AR players will be able to join the same game and interact together.
4. (2021) Multiplayer Mixed Reality Unity Sample Project + Azure Kinect
This will be an extension of the previous sample project but updated to handle an Azure Kinect.
The nifty part is that you will be able to connect an Azure Kinect through SSP to the game and the results of the Microsoft Body Tracking algorithm will be input into a game object that can be seen by all players.
5. (2021) Visual Positioning Service AKA RaaS (Reality As a Service) API
Stream sensor data with the SSP to our servers and we will send back the relative position of the streams. Now you can have superior multi-user experiences.
And (eventually 🙄), you will be able to stream us all the sensor data you got, and we will provide you with a digital representation of everything it covers.
Read our post on the benefits of edge processing architecture.
Please reach out to let us know what you think of our approach or if you want to help out.
[1] Important to note that this applies to situations where the device is in a new place- where it cannot find its relative position to a known “map”.
Quelle:
https://medium.com/@moetsi/benefits-of-an-edge-processing-architecture-in-mixed-reality-1bcaf519b1b8

